由来
最近有同事在用 ab 进行服务压测,到 QPS 瓶颈后怀疑是起压机的问题,来跟我借测试机,于是我就趁机分析了一波起压机可能成为压测瓶颈的可能,除了网络 I/O、机器性能外,还考虑到了网络协议的问题。
当然本文的主角并不是压测,后来分析证明同事果然还是想多了,瓶颈是在服务端。
分析起压机瓶颈的过程中,对于 TCP TIME_WAIT 状态的一个猜想引起了我的兴趣。由于之前排查问题时,简单地接触过这个状态,但并未深入了解,于是决定抽时间分析一下,拆解一下我的猜想。
转载随意,文章会持续修订,请注明来源地址:https://zhenbianshu.github.io 。
TCP 的状态转换
我们都知道 TCP 的三次握手,四次挥手,说来简单,但在不稳定的物理网络中,每一个动作都有可能失败,为了保证数据被有效传输,TCP 的具体实现中也加入了很多对这些异常状况的处理。
状态分析
先用一张图来回想一下 TCP 的状态转换。
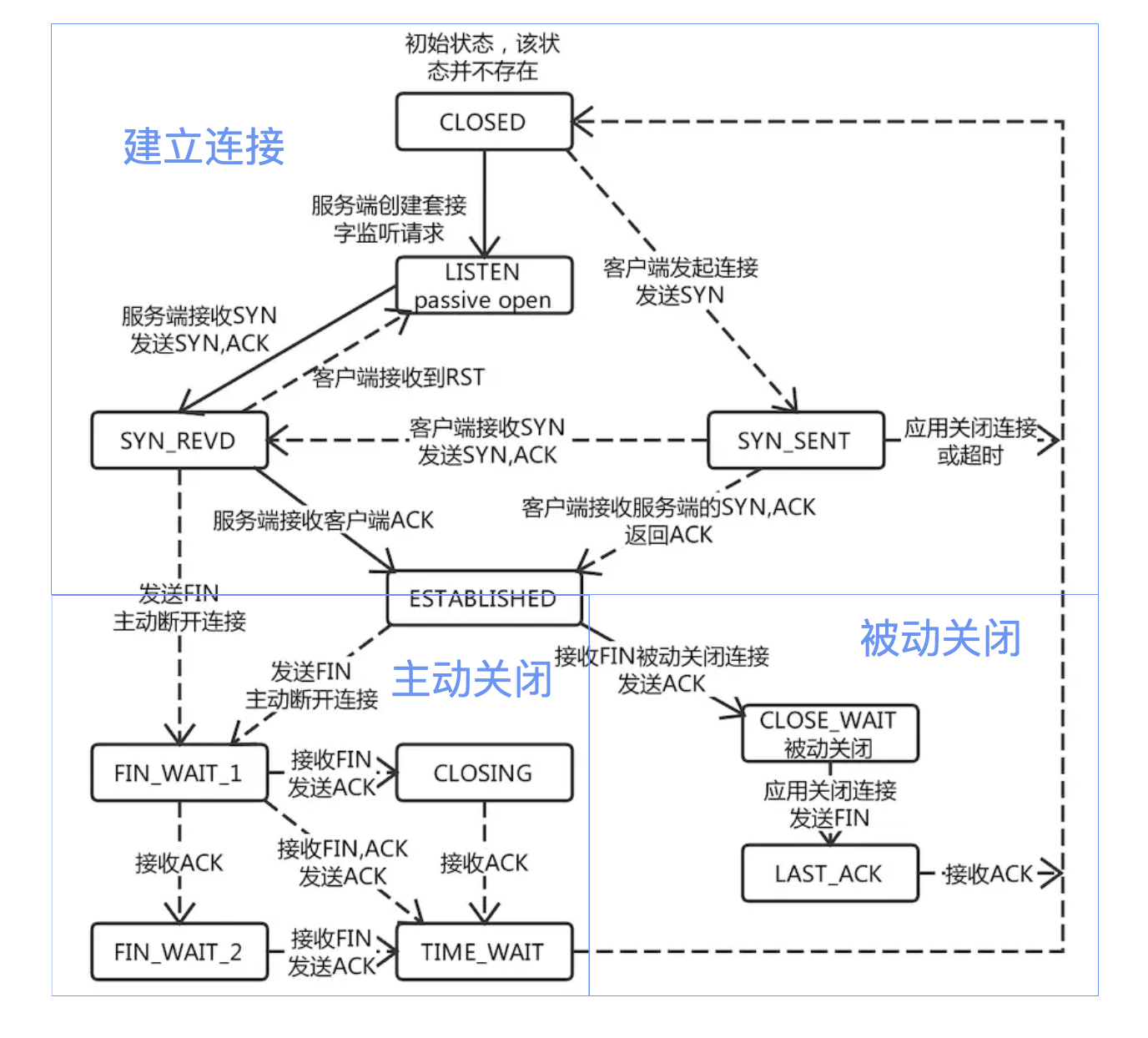
一眼看上去,这么多种状态,各个方向的连线,让人感觉有点懵。但细细分析下来,还是有理可循的。
首先,整个图可以被划分为三个部分,即上半部分建连过程,左下部分主动关闭连接过程和右下部分被动关闭连接过程。
再来看各个部分:建连过程就是我们熟悉的三次握手,只是这张图上多了一个服务端会存在的 LISTEN 状态;而主动关闭连接和被动关闭连接,都是四次挥手的过程。
查看连接状态
在 Linux 上,我们常用 netstat 来查看网络连接的状态。当然我们还可以使用更快捷高效的 ss (Socket Statistics) 来替代 netstat。
这两个工具都会列出此时机器上的 socket 连接的状态,通过简单的统计就可以分析出此时服务器的网络状态。
TIME_WAIT
定义
我们从上面的图中可以看出来,当 TCP 连接主动关闭时,都会经过 TIME_WAIT 状态。而且我们在机器上 curl 一个 url 创建一个 TCP 连接后,使用 ss 等工具可以在一定时长内持续观察到这个连续处于 TIME_WAIT 状态。
所以TIME_WAIT 是这么一种状态:TCP 四次握手结束后,连接双方都不再交换消息,但主动关闭的一方保持这个连接在一段时间内不可用。
那么,保持这么一个状态有什么用呢?
原因
上文中提到过,对于复杂的网络状态,TCP 的实现提出了多种应对措施,TIME_WAIT 状态的提出就是为了应对其中一种异常状况。
为了理解 TIME_WAIT 状态的必要性,我们先来假设没有这么一种状态会导致的问题。暂以 A、B 来代指 TCP 连接的两端,A 为主动关闭的一端。
-
四次挥手中,A 发 FIN, B 响应 ACK,B 再发 FIN,A 响应 ACK 实现连接的关闭。而如果 A 响应的 ACK 包丢失,B 会以为 A 没有收到自己的关闭请求,然后会重试向 A 再发 FIN 包。
如果没有 TIME_WAIT 状态,A 不再保存这个连接的信息,收到一个不存在的连接的包,A 会响应 RST 包,导致 B 端异常响应。
此时, TIME_WAIT 是为了保证全双工的 TCP 连接正常终止。
-
我们还知道,TCP 下的 IP 层协议是无法保证包传输的先后顺序的。如果双方挥手之后,一个网络四元组(src/dst ip/port)被回收,而此时网络中还有一个迟到的数据包没有被 B 接收,A 应用程序又立刻使用了同样的四元组再创建了一个新的连接后,这个迟到的数据包才到达 B,那么这个数据包就会让 B 以为是 A 刚发过来的。
此时, TIME_WAIT 的存在是为了保证网络中迷失的数据包正常过期。
由以上两个原因,TIME_WAIT 状态的存在是非常有意义的。
时长的确定
由原因来推实现,TIME_WAIT 状态的保持时长也就可以理解了。确定 TIME_WAIT 的时长主要考虑上文的第二种情况,保证关闭连接后这个连接在网络中的所有数据包都过期。
说到过期时间,不得不提另一个概念: 最大分段寿命(MSL, Maximum Segment Lifetime),它表示一个 TCP 分段可以存在于互联网系统中的最大时间,由 TCP 的实现,超出这个寿命的分片都会被丢弃。
TIME_WAIT 状态由主动关闭的 A 来保持,那么我们来考虑对于 A 来说,可能接到上一个连接的数据包的最大时长:A 刚发出的数据包,能保持 MSL 时长的寿命,它到了 B 端后,B 端由于关闭连接了,会响应 RST 包,这个 RST 包最长也会在 MSL 时长后到达 A,那么 A 端只要保持 TIME_WAIT 到达 2MS 就能保证网络中这个连接的包都会消失。
MSL 的时长被 RFC 定义为 2分钟,但在不同的 unix 实现上,这个值不并确定,我们常用的 centOS 上,它被定义为 30s,我们可以通过 /proc/sys/net/ipv4/tcp_fin_timeout 这个文件查看和修改这个值。
ab 的”奇怪”表现
猜想
由上文,我们知道由于 TIME_WAIT 的存在,每个连接被主动关闭后,这个连接就要保留 2MSL(60s) 时长,一个网络四元组也要被冻结 60s。而我们机器默认可被分配的端口号约有 30000 个(可通过 /proc/sys/net/ipv4/ip_local_port_range 文件查看)。
那么如果我们使用 curl 对服务器请求时,作为客户端,都要使用本机的一个端口号,所有的端口号分配到 60s 内,每秒就要控制在 500 QPS,再多了,系统就无法再分配端口号了。
可是在使用 ab 进行压测时时,以每秒 4000 的 QPS 运行几分钟,起压机照样正常工作,使用 ss 查看连接详情时,发现一个 TIME_WAIT 状态的连接都没有。
分析
一开始我以为是 ab 使用了连接复用等技术,仔细查看了 ss 的输出发现本地端口号一直在变,到底是怎么回事呢?
于是,我在一台测试机启动了一个简单的服务,端口号 8090,然后在另一台机器上起压,并同时用 tcpdump 抓包。
结果发现,第一个 FIN 包都是由服务器发送的,即 ab 不会主动关闭连接。
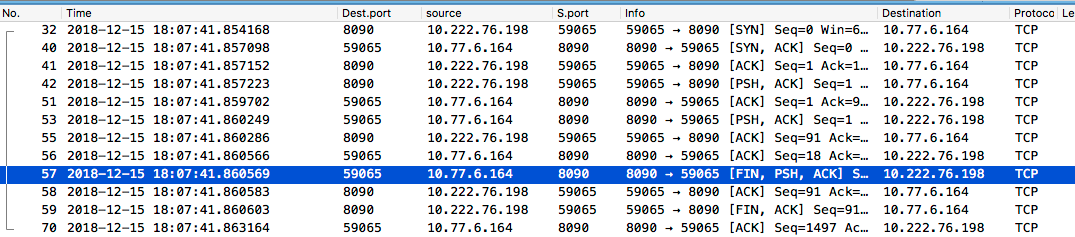
登上服务器一看,果然,有大量的 TIME_WAIT 状态的连接。
但是由于服务器监听的端口会复用,这些 TIME_WAIT 状态的连接并不会对服务器造成太大影响,只是会占用一些系统资源。
小结
当然,高并发情况下,太多的 TIME_WAIT 也会给服务器造成很大的压力,毕竟维护这么多 socket 也是要消耗资源的,关于如何解决 TIME_WAIT 过多的问题,可以看 tcp短连接TIME_WAIT问题解决方法大全(1)——高屋建瓴。
多了解原理遇到问题才能更快地找到根源解决,网络相关的知识还要继续巩固啊。
关于本文有什么疑问可以在下面留言交流,如果您觉得本文对您有帮助,欢迎关注我的 微博 或 GitHub 。您也可以在我的 博客REPO 右上角点击 Watch 并选择 Releases only 项来 订阅 我的博客,有新文章发布会第一时间通知您。